The Event-Related Potential¶
Synopsis
Data: 1 s of scalp EEG data sampled at 500 Hz during 1,000 trials in two conditions.
Goal: Characterize the response of the EEG in the two conditions.
Tools: Visualization, event-related potential, confidence intervals, bootstrapping.
Before we start any computations, let’s import some modules and functions that we will use throughout the notebook. A module can be imported any time, but there are a few things that we know we will need straight off the bat. For clarity, it is best practice to import packages at the beginning.
from scipy.io import loadmat # Import function to read data.
from pylab import * # Import numerical and plotting functions
from IPython.lib.display import YouTubeVideo # Enable YouTube videos
rcParams['figure.figsize']=(12,3) # Change the default figure size
On-ramp: computing the event-related potential in Python¶
We begin this notebook with an “on-ramp” to analysis. The purpose of this on-ramp is to introduce you immediately to a core concept in this notebook: how to compute an event-related potential with error bars in Python. You may not understand all aspects of the program here, but that’s not the point. Instead, the purpose of this on-ramp is to illustrate what can be done. Our advice is to simply run the code below and see what happens …
data = loadmat('matfiles/02_EEG-1.mat') # Load the data,
EEGa = data['EEGa'] # ... and get the EEG from one condition,
t = data['t'][0] # ... and a time axis,
ntrials = len(EEGa) # ... and compute the number of trials.
mn = EEGa.mean(0) # Compute the mean signal across trials (the ERP).
sd = EEGa.std(0) # Compute the std of the signal across trials.
sdmn = sd / sqrt(ntrials) # Compute the std of the mean.
plot(t, mn, 'k', lw=3) # Plot the ERP of condition A,
plot(t, mn + 2 * sdmn, 'k:', lw=1) # ... and include the upper CI,
plot(t, mn - 2 * sdmn, 'k:', lw=1) # ... and the lower CI.
xlabel('Time [s]') # Label the axes,
ylabel('Voltage [$\mu$ V]')
title('ERP of condition A') # ... provide a useful title,
show() # ... and show the plot.
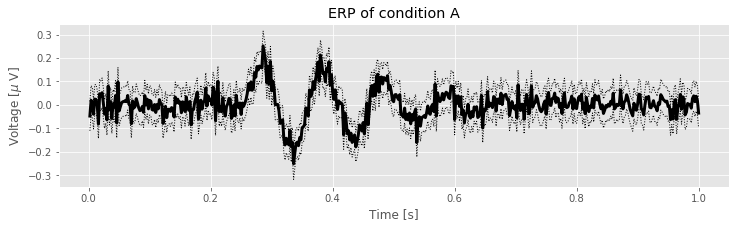
Q: Try to read the code above. Can you see how it loads data, computes the event-related potential and error, and then plots the results?
A: If you’ve never computed an event-related potential before, that’s an especially difficult question. Please continue on to learn this and more!
Background¶
YouTubeVideo('Cy_BF7smAkk')
Voltage recordings from the scalp surface - the electroencephalogram or EEG - provide a powerful window into brain voltage activity. Some of the earliest human EEG recording occurred in 1924, when Dr. Hans Berger made a remarkable discovery: the EEG of a human subject at rest with eyes closed exhibits rhythmic activity, an approximately 10 Hz oscillation he labeled the alpha rhythm. Although now studied for nearly 100 years, the definitive functional role (if any) of the alpha rhythm remains unknown. Since then, many other EEG rhythms have been detected and labelled (typically with Greek letters) and the analysis of EEG rhythms remains an active area of research.
Compared to other modalities for measuring brain activity, the EEG possesses both advantages and disadvantages. Perhaps the most important advantages are:
The EEG is non-invasive, and
The EEG permits a high temporal resolution (on the order of milliseconds).
However, the EEG measure also suffers from significant disadvantages, the most devastating being the poor spatial resolution; a single scalp electrode detects the summed activity from approximately 10 cm2 of cortex.
In this notebook, we consider EEG data recorded from a single scalp electrode. We will analyze these data to determine what (if any) activity is evoked following two different types of stimuli presented to a human subject. In doing so, we will use Python, and see how this powerful tool can help us understand these time series data. We begin with a brief description of the EEG data.
Case Study: an EEG ERP task¶
YouTubeVideo('q2-DjvPRaNA')
An undergraduate student volunteers to participate in a psychology study at his university. In this study, EEG electrodes (sampling rate 500 Hz, i.e., 500 samples per second) are placed on the student’s scalp, and he is seated in a comfortable chair in a dark, electrically isolated room. The student is instructed to place headphones over his ears and listen to a series of repeated sounds. The sounds consist of two tones - either a high pitch tone or a low pitch tone. A single tone is presented once every few seconds, and the student responds with a button press to the low pitch tone. The tone presentation is repeated to collect the EEG response to numerous presentations of the two tones, as illustrated here:
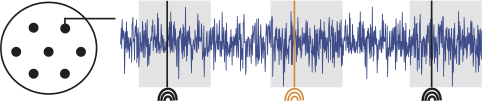
In this cartoon illustration of the EEG experiment, the EEG electrodes are placed on the scalp surface of a human subject (left). The EEG activity (blue) is recorded as a function of time during presentation of high pitch tones (black) and low pitch tones (orange).
Our collaborator leading this research study has agreed to provide us with EEG data recorded at a single electrode for 1000 presentations of the high pitch tone, and 1000 presentations of the low pitch tone. In each presentation - or “trial” - she provides us with 1 s of EEG data, such that the tone occurs at 0.25 s into the trial. She asks us to analyze these data to determine whether the EEG signal differs following the two tone presentations.
Data Analysis¶
Our first step is to load the data into Python. To do so, we use the function loadmat() from the scipy.io module as follows:
from scipy.io import loadmat # Import function to read data.
data = loadmat('matfiles/02_EEG-1.mat')
To understand the outcome of issuing this command, let’s examine the variable data now present in the workspace. This variable is a dictionary variable (to see this, execute type(data)). To see the keys of a dictionary, use the keys() method.
data.keys()
dict_keys(['__header__', '__version__', '__globals__', 'EEGa', 'EEGb', 't'])
The keys that start and end with two underscores ( __ ) are private and contain information about the MATLAB file; we will not need those keys here. The variables that we are interested in here are EEGa, EEGb, and t. These correspond to the EEG data recorded in the two conditions (i.e., EEGa to condition A and EEGb to condition B) as well as a time axis (t). Let’s extract these variables from the data dictionary.
EEGa = data['EEGa']
EEGb = data['EEGb']
t = data['t'][0]
You may notice that we specified index zero when we imported the variable t. This is because t is a vector (one-dimensional) rather than an array (multi-dimensional). The default behavior of loadmat() is to extract variables as ndarray types (to see this, execute type(EEGa)). Specifically, if we don’t tell Python to import the zeroth (row) element of data['t'] then t will have shape (1, 500), rather than (500,). There may be cases where this arrangement is preferred, but best practice is to convert the variable to a one-diminsional vector.
print(data['t'].shape)
print(t.shape)
print(len(data['t']))
print(len(data['t'][0]))
(1, 500)
(500,)
1
500
In general, a single underscore at the beginning of a variable, function or method indicates that this object should be treated as private. Double underscores often indicate that Python will interpret this object with some special instructions. In both cases, for what we are doing, we can usually ignore an object that starts with an underscore.
Let’s use the whos command to get some more information about the variables.
whos
Variable Type Data/Info
--------------------------------------------------
EEGa ndarray 1000x500: 500000 elems, type `float64`, 4000000 bytes (3.814697265625 Mb)
EEGb ndarray 1000x500: 500000 elems, type `float64`, 4000000 bytes (3.814697265625 Mb)
data dict n=6
fft function <function fft at 0x1149640e0>
linalg module <module 'numpy.linalg.lin<...>/numpy/linalg/linalg.py'>
mn ndarray 500: 500 elems, type `float64`, 4000 bytes
ntrials int 1000
power builtin_function_or_method <built-in method power of<...>te object at 0x1149318d0>
random builtin_function_or_method <built-in method random o<...>te object at 0x1149318d0>
sd ndarray 500: 500 elems, type `float64`, 4000 bytes
sdmn ndarray 500: 500 elems, type `float64`, 4000 bytes
t ndarray 500: 500 elems, type `float64`, 4000 bytes
We could also have used EEGa.shape to find out the dimensions of the variable EEGa.
In the Data/Info column we see 1000x500 for EEGa and EEGb. Both variables are matrices with 1000 rows and 500 columns. Our collaborator tells us that:
each row corresponds to a separate trial, and
each column to a point in time.
So there are 1000 total trials, each consisting of 500 time points. As a matter of convenience, we define a new variable to record the number of trials:
ntrials = EEGa.shape[0] # len(EEGa) would give the same result
The shape property of an array is a tuple that indicates the size of each dimension. Adding [0] at the end tells Python to give us only the first value in the tuple. Recall that Python indexing starts at 0. This variable will be useful later, as we’ll see. In fact, we can assign two variables at the same time:
ntrials, nsamples = EEGa.shape
With this syntax:
we assign the variable
ntrialsto the valueEEGa.shape[0], which is the number of rows.we assign the variable
nsamplesto the valueEEGa.shape[1], which is the number of columns.
Q. Determine the size of the variable EEGb. How many rows and columns does it possess? Which dimension corresponds to trials and which corresponds to time?
A tuple is another data structure in Python that is similar to an array or a list because it usually contains more than one element. Python treats each of these structures slightly differently, however. One of the most challenging things about starting with Python is learning to understand the different data structures. Here, we will mainly work with arrays, which are good for holding multidimensional data. If you are curious and want to know more about data structures, there is a very concise description here to get you started.
Visual Inspection¶
YouTubeVideo('uSjd41G-yNY')
Both EEGb and EEGa are complicated variables that contain many elements. To understand these data, we might attempt to read the values contained in each element. For example, we can print out the EEG data for the first trial of condition A
print( EEGa[0] ) # EEGa[0, :] is equivalent to EEGa[0]
[-1.85909632e-01 4.49876010e-01 1.06070801e+00 -4.71265246e-01
1.68669327e+00 9.38221338e-01 2.21207038e-01 4.05491276e-01
8.78879665e-01 5.23697825e-01 -2.35240678e+00 -9.24345879e-01
7.66671797e-01 -4.64254999e-01 6.25953180e-02 1.51917029e+00
-7.76400815e-01 8.14988739e-01 -1.58137285e-01 -6.17402518e-01
2.07506393e-01 3.59430871e-01 -1.21455008e+00 -6.16715452e-01
-4.81362032e-02 3.17982689e-01 -2.77459585e-01 4.14839815e-02
-1.52257779e+00 1.31993666e+00 1.46836023e+00 1.84666100e+00
5.23163980e-02 2.05515379e-01 2.27994679e-01 -1.34063464e+00
5.61451651e-01 1.20391968e+00 1.06398658e+00 4.38748238e-01
1.64443736e+00 -1.54713823e+00 6.41177787e-01 -1.13319311e+00
1.06869889e+00 3.88678297e-01 -1.86251056e+00 -1.14074604e+00
-4.59323117e-01 7.46220184e-01 4.40752835e-01 -7.05129357e-01
-1.85879610e-01 -4.52021194e-02 -7.74389189e-01 1.55051475e+00
1.12600755e+00 -1.14703552e+00 -5.42577409e-02 8.27809465e-01
8.56502531e-01 -1.14366915e+00 -8.19876772e-01 1.43053099e+00
3.58257978e-01 -3.63287337e-01 2.95693239e-01 1.66255457e+00
-1.81447543e+00 -5.63326663e-01 2.93117130e-01 -1.68396270e+00
-1.62231509e-01 -1.00251701e+00 -9.48001461e-01 3.16019127e-02
2.21147695e-01 3.99303915e-01 1.00913940e-01 1.21148596e+00
7.96770791e-01 1.66308465e+00 -6.46124699e-01 -1.02735954e-01
3.99807249e-01 2.03571783e-01 1.26714525e+00 -4.04535735e-01
-8.58928288e-02 3.81672240e-01 -8.10521508e-01 5.62971518e-01
-1.50312432e-01 2.16392074e+00 -7.56258314e-01 1.78649753e+00
-5.76044830e-01 2.70405891e-02 -1.77661427e-01 -8.66317207e-01
-2.71389551e-01 -3.89374337e-01 1.32780017e+00 6.56102489e-01
-6.17931971e-01 4.38460156e-01 4.96160421e-01 -2.43224802e-01
-7.59665353e-01 2.12561928e-01 -5.29236003e-01 -7.79237099e-01
-3.99720441e-01 -5.73857423e-01 1.68557371e-02 -3.33452422e-01
5.49266775e-02 -8.05679798e-01 3.48038611e-01 1.10559489e+00
1.58877419e-01 4.26861264e-01 -3.58946165e-01 1.49418999e+00
9.00513782e-01 -8.29008444e-01 2.26386025e+00 -5.42571448e-01
1.51343144e+00 -6.21544949e-01 -7.22549599e-01 3.21016398e-01
1.28741129e-01 1.27751490e+00 -7.49605666e-01 1.52310976e+00
-6.86917819e-03 -2.54194745e-01 1.00352371e+00 -5.12364395e-01
1.66279331e-01 -1.69990836e+00 -1.85635884e+00 3.02517825e-01
5.55141950e-02 4.32485593e-01 -2.74367743e+00 -2.81457510e-01
8.14989513e-01 2.61966455e-01 1.04412960e+00 9.65418636e-01
3.41587255e-01 -1.88010279e-01 -8.39449139e-01 6.33492347e-01
-1.24757135e+00 1.31337736e+00 -6.22469263e-01 1.09149506e+00
-1.09034016e+00 3.76813749e-01 -3.18257114e-01 2.61894031e+00
-2.76705198e-01 4.42140552e-01 -1.43555653e+00 7.85517143e-01
-9.88738053e-01 6.72988002e-01 8.68360705e-01 3.13242062e-01
-1.54828005e-01 1.17732668e+00 4.02575413e-01 -2.25480529e-01
2.72944171e-01 -7.02691389e-01 -2.31377386e+00 -2.22783195e-01
-1.35413650e+00 -1.15072542e+00 -2.88073430e-01 1.81260388e-01
-2.23623245e-01 -1.94225711e-01 -5.57725111e-01 8.91721155e-01
1.16596501e-01 2.63088800e-01 -7.05166127e-01 4.08335180e-01
-7.90285417e-01 9.51082199e-01 2.10206983e+00 -1.47579554e-01
-4.84839924e-01 1.60258306e+00 8.81078598e-02 3.61369070e-01
2.27598177e-02 3.17643233e-01 7.36130484e-02 1.37376140e+00
7.61866764e-01 -3.98162196e-01 -1.31208258e+00 -7.31528581e-01
-1.07254213e+00 1.22320138e+00 -2.58565701e+00 -1.14526894e+00
-4.33488841e-01 -4.39707520e-01 -1.03812489e+00 -2.62273457e-01
6.38441158e-01 8.12705883e-01 -8.18589118e-01 -1.08256005e+00
-3.80301239e-01 -6.89096543e-01 2.39683506e-01 8.50289735e-01
-7.26308358e-01 -4.91580776e-01 1.03219979e+00 1.12525973e-01
-5.71141273e-01 6.18952595e-02 1.09705291e+00 7.85887270e-01
-1.85564767e-01 1.14603225e+00 -2.06964423e+00 -4.38792883e-01
1.74227196e+00 1.94092238e-01 -1.47258884e+00 -6.41420839e-01
6.72742297e-02 -1.58340914e-02 1.37746846e+00 -2.56196901e-01
-5.67582665e-01 5.37033982e-01 -5.44631235e-01 3.23707432e-01
1.61864414e+00 6.64638714e-02 -1.06040359e+00 5.45961175e-02
3.93434967e-02 -1.05920809e+00 -2.98790912e-01 2.22548242e+00
2.24405511e-01 -5.42362119e-01 5.22628043e-01 1.10073489e+00
-4.75832910e-01 -1.48245524e+00 -5.19264968e-01 8.66583703e-01
3.71195522e-01 -2.10862001e+00 1.41854997e+00 -4.00056944e-01
-1.04638985e+00 -2.23544462e-03 -5.98113911e-01 -7.59605516e-01
-9.26386972e-01 -2.18387895e-01 -1.09959119e+00 3.36465936e-01
-7.19877563e-01 9.42514084e-01 -4.25416496e-01 3.79620259e-01
-1.70723125e+00 1.06572378e-02 -2.35473140e-01 4.54021576e-01
-1.02334158e+00 -1.38240225e-01 3.48629888e-01 -2.68704032e-01
5.91463529e-01 -1.78286801e-01 1.02320933e+00 -7.07756343e-01
-1.16006916e+00 1.91717624e+00 -1.23381123e-01 -2.68528533e-01
-1.14265441e+00 1.36823726e+00 1.77076815e-01 1.20573044e+00
1.41205843e+00 -2.15337976e+00 6.00658920e-01 1.15495770e-01
-1.31467338e+00 -5.09848812e-01 -4.70210648e-01 -1.95764263e+00
1.46093909e+00 1.31264582e+00 2.08027524e+00 -2.83817742e-02
-3.34822927e-02 5.97081623e-02 -2.41728231e+00 -2.06588056e+00
-1.74279194e-01 2.06744443e-01 -1.09047610e+00 -1.19118680e-01
4.01697824e-01 3.02122302e-01 3.34421161e-01 -1.10831100e+00
-9.20222909e-01 2.32218615e-01 -2.55154972e-01 -3.14863316e-01
-1.59970267e+00 4.36780490e-01 5.65896649e-01 -9.78787106e-01
1.22855597e+00 7.58542962e-01 5.58518929e-01 -6.29520116e-02
1.18742536e+00 1.18562777e+00 1.42177066e+00 -1.06696561e+00
-1.78054659e+00 -8.24179662e-01 1.72242837e+00 -1.13652998e+00
-2.74037314e-01 -1.61735137e+00 1.76740867e+00 -1.36302046e+00
-1.24542747e+00 -1.10195479e+00 4.97427770e-01 3.40747285e-01
1.29469407e+00 -1.68192736e-01 -1.58189637e+00 3.32752964e-01
2.06914282e-01 -8.33433942e-01 -1.20097677e+00 4.09469512e-01
-5.56735550e-01 -2.86558705e-02 -8.96614175e-01 -2.22091771e+00
-1.34815359e+00 6.51385061e-01 1.36132110e+00 5.12259438e-01
1.15080616e+00 -9.45816812e-01 3.48666490e-01 1.29115601e+00
1.13964510e+00 1.13056053e+00 -7.28460179e-02 1.58127482e+00
8.66434530e-01 -1.77527248e-01 -4.01926432e-01 1.61406298e+00
1.93971032e+00 1.75279276e+00 -2.56648516e+00 -9.33356759e-01
-2.54317956e-01 -1.13741045e-01 4.05204253e-01 -1.43414289e+00
-1.37124663e+00 8.71688411e-01 9.86925920e-01 1.58442262e-01
1.10944234e+00 -2.60888891e-01 -4.94844677e-01 2.10364682e-01
-6.90648659e-01 9.44229553e-01 -1.67842868e+00 9.94333574e-01
-5.42498176e-02 -6.10670786e-01 3.40630320e-01 -1.32665190e+00
-6.35411807e-01 1.82564630e-01 1.03543428e+00 9.70748027e-02
-5.46855555e-01 -3.30881410e+00 -4.63280602e-01 2.24579407e-01
-2.24752515e+00 9.98283459e-01 -1.06182712e+00 -3.46684931e-02
1.41764225e+00 -1.24954136e+00 -6.18775586e-01 -5.11007703e-01
-9.14202212e-01 -3.01515892e-01 -1.59706594e+00 2.40487958e-01
1.59654644e-03 5.03777332e-01 1.84766666e-01 3.90711577e-01
2.27690541e+00 -1.67938680e+00 1.52788636e+00 -1.68420319e+00
-5.06769300e-01 1.19757238e+00 -2.78010488e-01 6.86491400e-02
-5.39049209e-01 -1.29632687e-01 3.14379167e-01 6.84138095e-01
9.36048610e-01 -1.45547151e+00 -2.69117642e-01 4.91635711e-01
-9.69470971e-01 1.83872986e+00 8.19492008e-01 -4.22742826e-01
-1.02695268e-01 3.65153939e-01 -4.40593064e-01 -6.06052965e-01
4.75034049e-01 -1.21577077e+00 -9.68793697e-01 -6.46342514e-01
1.08533369e+00 -2.19535994e-01 -1.19895690e-01 1.98995688e-01
6.82348483e-01 -1.10943112e-01 1.19046834e-01 6.71215306e-01
-9.96084629e-01 1.34367623e+00 1.62036945e+00 -5.62949996e-01
-8.61888584e-01 1.49041285e+00 -7.57353843e-01 4.98675751e-01
-2.50954448e-01 -1.79724228e+00 -1.35719865e+00 1.05713585e+00
-1.05491807e-01 4.63733007e-01 -2.16122922e-01 -7.99948330e-01
-6.55124881e-01 -2.24820127e+00 2.37631176e-01 -9.71408307e-01
-7.66843512e-01 -2.70585493e-01 -1.11657661e+00 1.25282149e+00
-1.60574278e+00 -2.23134272e+00 9.09836712e-01 8.87246449e-01
-1.72687413e+00 5.94455670e-01 -6.35422508e-01 9.86293109e-01
-9.91015631e-01 -7.97709874e-01 -1.27420635e+00 8.67409389e-01]
In this command, we index the first row of the matrix EEGa and print out all columns (corresponding to all moments of time).
Q. Upon issuing this command what do you find? Does the printout help you understand these data?
A. You should observe a list of 500 numbers that begins
`-1.85909632e-01 4.49876010e-01 1.06070801e+00 -4.71265246e-01 1.68669327e+00 9.38221338e-01 ...`
We might conclude that these numbers exhibit variability (i.e., the values are both positive and negative), but examining the data in this way is not particularly useful. For example, determining trends in the behavior (such as intervals of repeated activity) through inspection of these printed numbers alone is extremely difficult.
YouTubeVideo('9qx29zDxcAc')
Printing out the data to the screen is not useful in this case. How else can we deepen our understanding of these data? Let’s make a plot:
plot(EEGa[0]) # Plot the data from condition A, trial 1.
savefig('imgs/2-2a')
show()
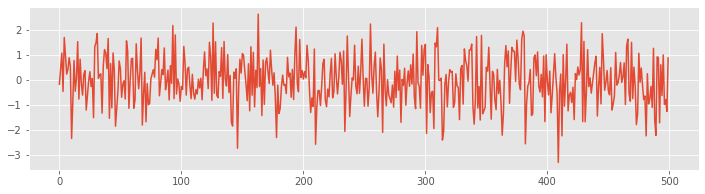
Visualizing the data in this way, we immediately notice many features. First, let’s consider the axes. The horizontal axis extends from 0 to (nearly) 500. This corresponds to the 500 columns in the variable EEGa. While this visualization is useful, it would be more informative to plot the EEG data as a function of time rather than indices. Fortunately, we possess a variable t in the workspace that corresponds to the time axis. Determining the size of the variable t, we find it is a vector with 1 row and 500 columns. Each column corresponds to a point in time.
Q. Plot the variable t. What is its range?
The variable t corresponds to the 1 s of EEG data recorded in each trial. We can also use the variable t to determine the sampling interval,
dt = t[1] - t[0] # Determine the sampling interval
The new variable dt corresponds to the time between samples.
Q. What is the value of dt? We were told by our collaborator that the sampling frequency is 500 Hz. Is the value of dt consistent with this sampling frequency?
A. Yes, it is consistent. Using the command print(dt), we find that dt is 0.002 s, or 2 ms. The sampling frequency of 500 Hz corresponds to one sample of the EEG data every 1/(500 Hz) = 2 ms. If the two were not consistent, we would return to our collaborator and figure out what has gone wrong. In general, it’s useful to ask such questions along the way to make sure we understand the formatting of the data and catch any potentially serious misunderstandings early in the analysis.
We can now combine the time axis with the EEG data to make a more complete plot. Let’s also label the axes and give the plot a title.
plot(t, EEGa[0]) # Plot condition A, trial 1 data vs t.
xlabel('Time [s]') # Label the x-axis as time.
ylabel('Voltage [$\mu$ V]') # Label the y-axis as voltage.
title('EEG data from condition A, Trial 1') # Add a title
# Add a vertical line to indicate the stimulus time
plot([0.25, 0.25], [-4,4], 'k', lw=2)
savefig('imgs/2-2b')
show()
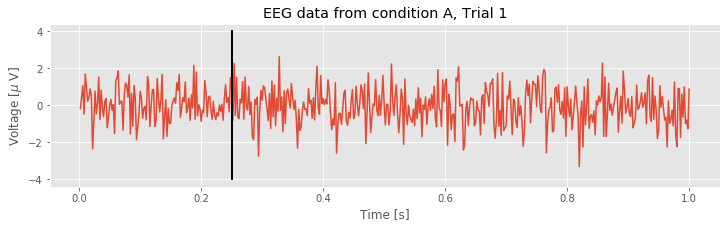
This plot provides a nice summary of the data in the first trial of condition A. Visual inspection of the plot suggests that these data exhibit complicated activity. We know from our collaborator that the stimulus occurs at time 0.25 s in each trial. Note how we indicated this time as a vertical line in the plot above. This command includes additional options that make the line black ('k') and a bit wider (lw=2).
Q. What else, if anything, can you say about the single trial of EEG data plotted above? Does the visual inspection reveal any particular change in the EEG activity following the stimulus presentation?
So far we have visualized only the data from condition A. Because we are interested in whether the EEG behaves differently in the two conditions, visualizing both conditions simultaneously would be of use. We can do this as follows:
figure(figsize=(12, 3)) # Resize the figure to make it easier to see
plot(t,EEGa[0]) # Plot condition A, trial 1, data vs t,
plot(t,EEGb[0], 'r') # ... and the data from condition B, trial 1,
xlabel('Time [s]') # Label the x-axis as time.
ylabel('Voltage [\mu V]') # Label the y-axis as voltage.
title('EEG data from conditions A (blue) and B (red), Trial 1') # And give it a title.
savefig('imgs/2-3')
show()
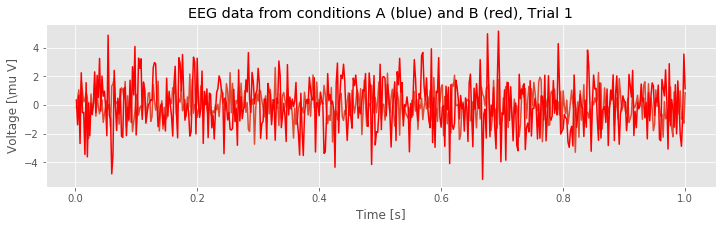
Q. Compare the voltage traces from the first trial of conditions A and B as plotted above. What similarities and differences do you observe?
Q. The analysis has so far focused only on the first trial. Repeat this visual inspection of the data for different trials. What do you find? What similarities and differences exist between the two conditions across trials?
YouTubeVideo('nandZ5aaRaQ')
These techniques allow us to visualize the data one trial at a time. That is useful but can be time consuming, especially for a large number of trials. For the EEG data of interest here, each condition contains 1,000 trials, and to visualize each trial separately could require 2,000 plots. We can certainly create 2,000 plots, but the subsequent visual inspection would be time consuming and difficult. Fortunately, a more efficient visualization approach exists: we can display the entire structure of the data across both time and trials as an image:
imshow(EEGa, # Image the data from condition A.
cmap='BuPu', # ... set the colormap (optional)
extent=[t[0], t[-1], 1, ntrials], # ... set axis limits (t[-1] represents the last element of t)
aspect='auto', # ... set aspect ratio
origin='lower') # ... put origin in lower left corner
xlabel('Time[s]') # Label the axes
ylabel('Trial #')
colorbar() # Show voltage to color mapping
vlines(0.25, 1, 1000, 'k', lw=2) # Indicate stimulus onset with line
savefig('imgs/2-4')
show()
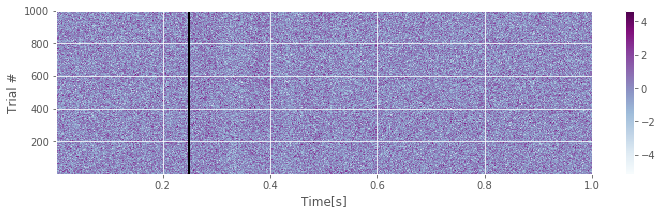
The imshow command allows us to visualize the entire matrix EEGa as a function of trial number and time. Each row corresponds to a single trial of duration 1 s, and the color indicates the voltage, with darker (lighter) colors indicating higher (lower) voltages. This plot also indicates the time of stimulus presentation with a vertical black line as a cue to assist visual inspection.
We have used the BuPu color map for the plot above. There are many other options; use colormaps? for details.
Q.
Upon close inspection of the figure above, what response, if any, do you observe following the stimulus presentation? (Look really carefully.) Repeat this visualization and analysis for EEGb. How do the two conditions compare?
Plotting the ERP¶
YouTubeVideo('kPr2GLSKLJg')
Visual inspection of the EEG data has so far come up empty. The EEG traces appear noisy or perhaps rhythmic, but from visual inspection of the individual trials it’s difficult to make a decisive conclusion of underlying structurefig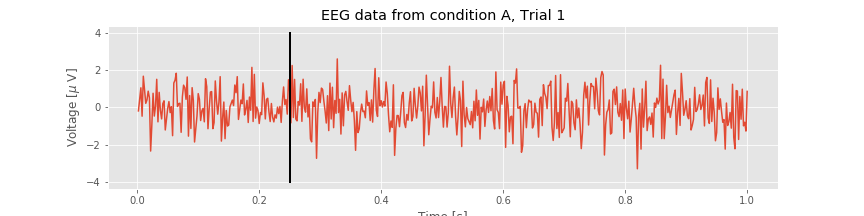 . To further investigate the activity in these data, we compute the event-related potential (ERP).
. To further investigate the activity in these data, we compute the event-related potential (ERP).
To compute the ERP, we first assume that each trial evokes an instantiation of the same underlying brain process. So, in this case, we assume that the same brain response is evoked 1,000 times (once for each trial) for each condition. However, the evoked response due to the stimulus is small and hidden in the EEG signal by other ongoing activity unrelated to the stimulus (e.g., daydreaming, thoughts of dinner, thoughts of homework). Therefore, to tease out the weak evoked effect, we average the EEG responses across trials. Ideally, EEG activity unrelated to the stimulus will cancel out in the average, while EEG activity evoked by the stimulus will sum constructively. The procedure to perform and display this averaging can be done in Python as follows:
plot(t, EEGa.mean(0)) # Plot the ERP of condition A
xlabel('Time [s]') # Label the axes
ylabel('Voltage [$\mu V$]')
title('ERP of condition A') # ... provide a title
savefig('imgs/2-5')
show() # ... and show the plot
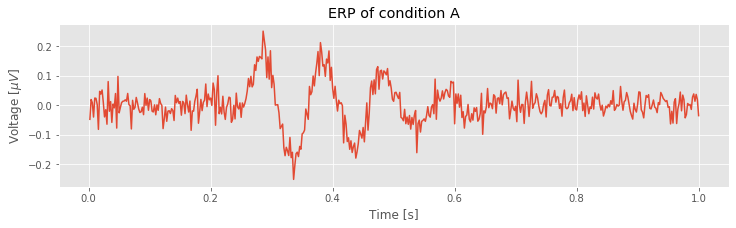
In the first line, we compute the mean of EEGa using the method mean() (see the documentation for this function here). The default behavior is to compute the mean of all elements of the array. By calling EEG.mean(0), we compute the mean along the zeroth dimension. The result is the ERP for condition A.
Q. Consider the ERP for condition A plotted above. Update this figure to include a vertical line at the location of the stimulus, and the ERP for condition B. How, if at all, do the ERPs for Conditions A and B differ?
The ERP of condition A shows the mean voltage across trials at each moment in time. Visual inspection suggests that before stimulus presentation (i.e., times 0 s to 0.25 s) the EEG fluctuates around zero. Then, after stimulus presentation, the ERP increases and decreases substantially above and below zero. Which, if any, of these deviations following stimulation are significant? To address this, we make use of the trial structure of the EEG data to compute confidence bounds for the ERP. We do so in two ways.
Confidence Intervals for the ERP (Method 1)¶
YouTubeVideo('pXCJbyrw8Ug')
To compute the ERP we average the EEG data across many trials. Because of this, we may make use of a powerful theorem in statistics—the central limit theorem (CLT)—to include approximate confidence bounds in the ERP figure. Briefly, this theorem states that the mean of a sufficiently large number of independent random variables, each with finite mean and variance, will be approximately normally distributed. Remember that the ERP at each moment in time is the sum of EEG activity across trials (then scaled by a constant, the number of trials). Let’s assume that the trials are independent (i.e., one trial does not depend on any other trial). Let’s also assume that the EEG data at each moment in time have finite mean and variance. With those assumptions, we have satisfied the CLT and may therefore conclude that the ERP at each moment in time is approximately normally distributed.
Q. To use the CLT, we make two assumptions about the EEG data. Are these assumptions reasonable?
A. We assume that the EEG data are independent across trials. This assumption may fail if, for example, the activity in one trial influences the activity in the next trial. We also assume that the EEG data are “well-behaved” (i.e., have finite mean and variance). That is a reasonable assumption for physical data we observe from the brain; we expect the EEG data to always remain finite and not diverge to plus or minus infinity.
This conclusion—that the ERP at each moment in time is approximately normally distributed—is useful because the normal distribution (also known as the Gaussian distribution or bell curve) possesses many convenient properties. First, a normal distribution is relatively simple; it can be completely specified with two parameters: the mean value and the standard deviation. Second, 95% of the values drawn from a normal distribution lie within approximately two standard deviations of the mean.
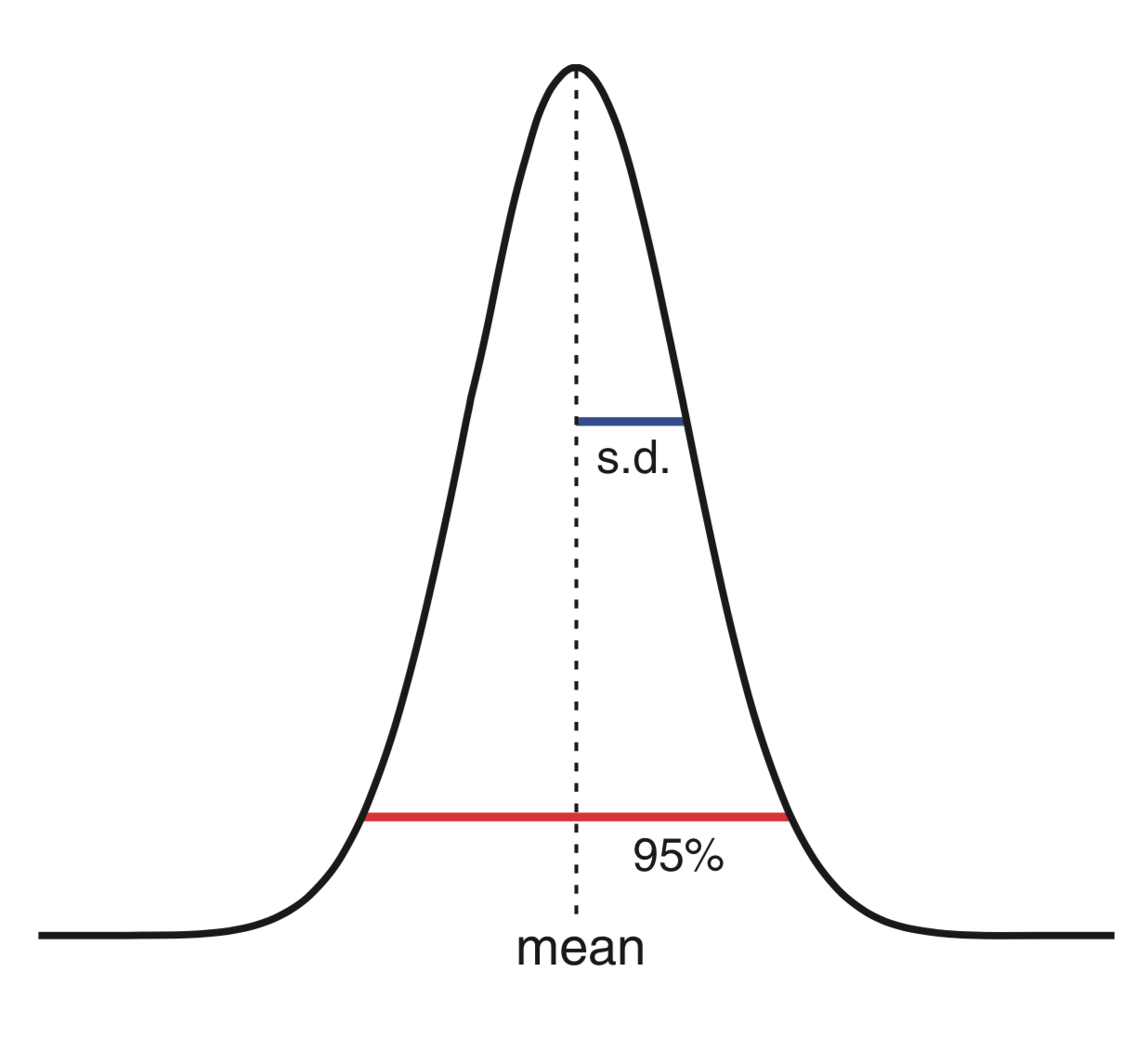
Here’s a plot of the canonical normal distribution showing the mean (dotted vertical line) and standard deviation (blue). Ninety-five percent of values lie within the interval indicated by the red bar.
Therefore, to construct a 95% confidence interval for the ERP, we need to determine the mean and standard deviation of the mean across trials at each point in time. To compute the mean in Python is easy:
mn = EEGa.mean(0) # Compute the mean across trials (the ERP)
Note that when we refer to the mean here we could instead write sample mean because we use the observed data to estimate the theoretical mean that we would see if we kept repeating this experiment. This distinction is not essential to our goals here, but it is important when talking to your statistics-minded colleagues. Throughout the book, we omit the term sample when referring to sample means, variances, covariances, and so forth, unless this distinction is essential to the discussion.
We again note that the second input to the mean function specifies the dimension in which we compute the mean, in this case, across the first dimension of the variable EEGa corresponding to the trials. To compute the standard deviation of the mean, we start by computing the standard deviation of the data:
sd = EEGa.std(0) # Compute the std across trials
But we’re not interested in the standard deviation of the EEG data across trials; instead, we’re interested in the standard deviation of the estimate of the mean. To calculate the standard deviation of the mean, we divide the standard deviation of the data by the square root of the number of trials (i.e., the number of terms used to compute the mean). In Python,
sdmn = sd / sqrt(ntrials) # Compute the std of the mean
Now, having found the mean (mn) and the standard deviation of the mean (sdmn), we can compute a 95% confidence interval for the ERP. We again exploit the observation, based on the central limit theorem, that the ERP is normally distributed at each instant of time. With these calculations, the following code plots the ERP and the 95% confidence interval:
fig, ax = subplots(figsize=(12, 3)) # Save the axes for use in later cells and resize the figure
ax.plot(t, mn, 'k', lw=3) # Plot the ERP of condition A
ax.plot(t, mn + 2 * sdmn, 'k:', lw=1) # ... and include the upper CI
ax.plot(t, mn - 2 * sdmn, 'k:', lw=1) # ... and the lower CI
xlabel('Time [s]') # Label the axes
ylabel('Voltage [$\mu$ V]')
title('ERP of condition A') # ... provide a useful title
fig # ... and show the plot
show()
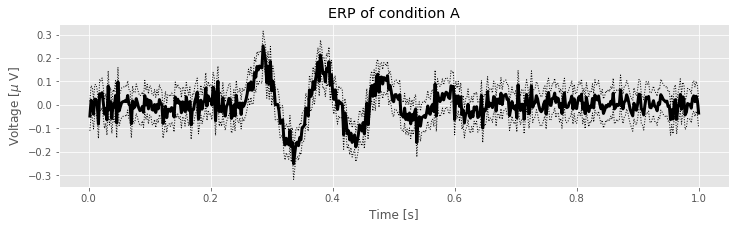
The ERP computed with confidence intervals allows us to ask specific questions about the data. For example, does the ERP ever differ significantly from zero? To answer this, we look for intervals of the ERP for which the confidence intervals do not include zero. To aid visual inspection, we add to the ERP plot a horizontal line at 0:
A good rule of thumb when you are programming is that you should not be rewriting (or copy-pasting) code over and over again. Instead, you should write a function that you can call whenever you need the action that you keep repeating. At this point, we have resized the plots and labeled the axes the same way several times so we should fix the default plot size and write a function that automates the labeling so that next time we make a plot, we don’t need to rewrite the same code again.
# Create a function to label plots
def labelPlot(title_string="Title"):
'''
A function that labels the x-axis as 'Time [s]' and
the y-axis as 'Voltage [$\mu V$]'.
Arguments:
title_string: string variable to be used as
the plot title (default: 'Title')
'''
xlabel('Time [s]') # x-axis is time
ylabel('Voltage [$/mu V$]') # y-axis is voltage
title(title_string) # use the input here
autoscale(tight=True) # no white-space in plot
Q. How would you write a function to compute the ERP and confidence bounds of a dataset?
Q. What do you think the following code will do?
`ax.hlines(0, t[0], t[-1])`
Try it out.
Q. What is the role of the method function hlines() in this code? Hint: If you have not encountered this function before, look it up in the Documentation.
ax.hlines(0, t[0], t[-1])
fig.savefig('imgs/2-7')
fig
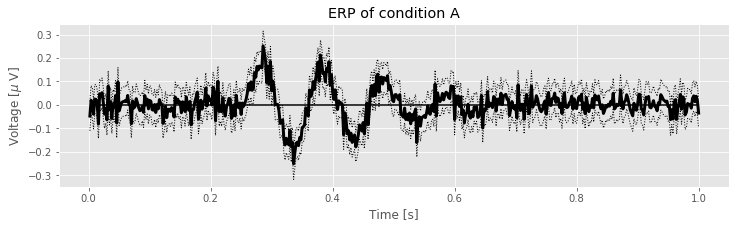
In the figure above, the thick line indicates the ERP for Condition A (i.e., the mean of the EEG across trials) while the thin dotted lines indicate the 95% confidence intervals.
We find three time intervals at which the confidence intervals of the ERP do not include zero: near 0.27 s, near 0.37 s, and near 0.47 s. These results suggest that for an interval of time following the stimulus presentation in condition A, the observed ERP is not a random fluctuation about zero but instead contains consistent structure across trials.
Q. Construct the ERP with confidence intervals for condition B. As for condition A, you should find that before stimulus presentation the ERP fluctuates around zero. What intervals of time, if any, differ significantly from zero?
Comparing ERPs¶
In the previous section, we implemented a procedure to compute confidence intervals for the ERPs in conditions A and B. To investigate differences between the ERPs in the two conditions, we can use a similar approach. To start, let’s plot the ERPs with confidence intervals for both conditions and attempt to identify periods for which the confidence intervals do not overlap (such intervals would correspond to significant differences between the responses of the two conditions).
from my_module import ERP # A function written by the author to compute the ERP
erpA, ca_l, ca_h = ERP(data['EEGa']) # Compute the ERP of condition A
erpB, cb_l, cb_h = ERP(data['EEGb']) # ... and condition B
plot(t, ca_l, 'r:', t, ca_h, 'r:') # Plot confidence bounds in back
plot(t, cb_l, 'b:', t, cb_h, 'b:')
plot(t, erpA, 'r', lw=3, label='condition A') # ... and ERPs in front
plot(t, erpB, 'b', lw=3, label='condition B')
labelPlot('ERP of conditions A and B')# Label axes
legend()
savefig('imgs/2-8a')
show()
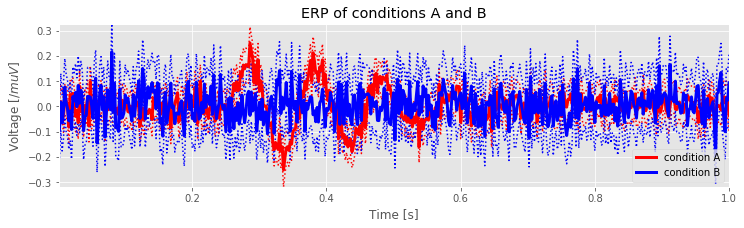
Q. In the cell above, the ERPs and confidence bounds are computed using a function written by the author. Can you write the code to make this plot yourself?
As you can see, the plot of both ERPs is rather messy; it’s difficult to determine through visual inspection alone in which intervals the ERPs exhibit significant separation.
To facilitate further inspection of the data, we compute the difference between the ERPs in the two conditions. In the differenced signal, large deviations between the two conditions will appear as large differences from zero. To determine whether a deviation is significantly different from zero, we need to determine the confidence interval for the differenced ERP. This requires we propagate the standard deviation of the mean for both ERPs to the new differenced ERP. The propagated standard deviation of the mean at a fixed moment in time is computed as:
\($ \sigma = \sqrt{\frac{\sigma_A^2}{K} + \frac{\sigma_B^2}{K}}, \tag{1} $\)
where \(\sigma_A\) is the standard deviation of the data from condition A, \(\sigma_B\) is the standard deviation of the data from condition B, and \(K\) is the number of trials.
In Python we compute the differenced ERP and standard deviation of the mean of the difference as follows:
mnA = EEGa.mean(0) # ERP of condition A
sdmnA = EEGa.std(0) / sqrt(ntrials) # ... and standard dev of mean
mnB = EEGb.mean(0) # ERP of condition B
sdmnB = EEGb.std(0) / sqrt(ntrials) # ... and standard dev of mean
mnD = mnA - mnB # Differenced ERP
sdmnD = sqrt(sdmnA ** 2 + sdmnB ** 2) # ... and its standard dev
plot(t, mnD, 'k', lw=3) # plot the differenced ERP
plot(t, mnD + 2 * sdmnD, 'k:') # ... the upper CI
plot(t, mnD - 2 * sdmnD, 'k:') # ... and the lower CI
plot([0, 1], [0, 0], 'b') # ... and a horizontal line at 0
labelPlot('Differenced ERP') # label the plot
show()
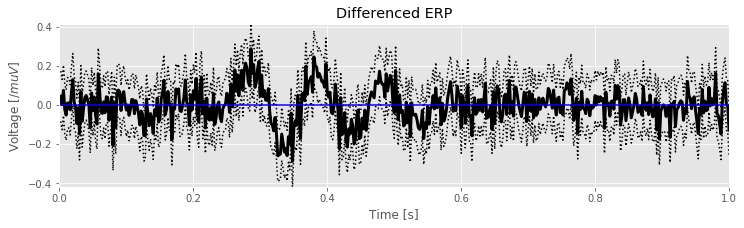
In the code above we first compute the ERP and standard deviation of the mean for each condition. We then compute the differenced ERP (mnD) and the standard deviation of the mean of this difference (sdmnD)eq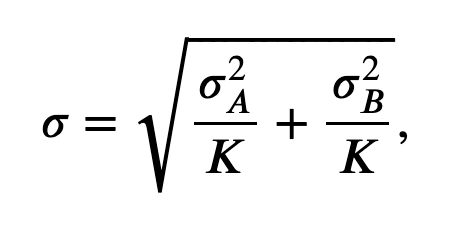 . We note that
. We note that sdmnA\(= \sqrt{\sigma_A^2/K}\) and therefore sdmnA**2 \(= \sigma_A^2/K\), with similar expressions for condition B. We then plotted the resulting differenced ERP with 95% confidence intervals. The hope is that from this figure we can more easily identify significant differences between the two conditions.
Q: Examine the plot of the differenced ERP. In what intervals of time do the EEG responses in the two conditions significantly differ?
Confidence Intervals for the ERP (Method 2)¶
YouTubeVideo('vVXH4XsPFEs')
So far we have computed confidence intervals for the ERPs by relying on the central limit theorem and approximating the average voltage values at each point in time as normally distributed. That’s a completely reasonable approach. And because the normal distribution is so well-behaved, it’s easy to compute the 95% confidence intervals. An alternative approach to generate confidence intervals is through a bootstrap procedure. Bootstrapping is a resampling method that allows us to estimate the sampling distribution of many different statistics. In this notebook, we implement a nonparametric bootstrap (see note). To do so, we generate new pseudodata from the observed EEG data. We begin by using a bootstrapping procedure to create confidence intervals for the ERPs observed in each condition.
A note on the nonparametric bootstrap. Briefly, there is strong theoretical justification for the nonparametric bootstrap. The fundamental idea is that resampling the data with replacement is equivalent to sampling new pseudodata from the empirical cumulative distribution function (eCDF) of the observed data. For a large sample of independent, identically distributed random variables, the distribution of the pseudodata generated from the eCDF will be close to the true distribution of the data. Note the important caveat that the variables are independent, identically distributed; this assumption fails in many cases, such as for time series. Here, we assume that each trial is drawn independently from the same distribution (i.e., the trials are independent, identically distributed variables).
We implement the bootstrapping procedure to compute pointwise confidence intervals. By pointwise we mean that the confidence intervals are computed separately for each point in time, and interactions across time are not considered. The prescription for the bootstrapping procedure follows four steps:
Sample with replacement 1,000 trials of the EEG data from condition A.
Average these 1,000 trials to create a resampled ERP.
Repeat these two steps 3,000 times to create a distribution of ERPs.
For each time point, identify the values greater than 2.5% and less than 97.5% of all 3,000 values. This range determines the 95% confidence interval for the ERP for that time point.
Let’s now implement each step in Python.
YouTubeVideo('mqDEJyW_z4c')
Step 1¶
In step 1 we must sample with replacement from the EEG data. To visualize this procedure, imagine placing 1,000 marbles in an opaque bag. Each marble is assigned a unique integer value from 1 to 1,000. Now, reach your hand into the bag, grab a marble, record its number, and replace the marble in the bag. We assume that each marble is equally likely to be selected at each draw (i.e., there are no special features that allow some marbles to be drawn more often). Repeat this procedure 1,000 times to create a list of 1,000 integers. Notice that after recording the drawn marble’s number, we replace it in the bag. So, we could potentially draw the same marble 1,000 times, although that’s extremely unlikely. Performing this sampling with replacement procedure by hand would, of course, be extremely time consuming (e.g., who will paint integers on each marble?). Fortunately, Python provides a function to perform sampling with replacement:
# Draw 1000 integers with replacement from [0, 1000)
i = randint(0, ntrials, size=ntrials)
The first and second inputs to randint() specify the minimum and maximum integers to draw, respectively. Note that the low number is included in the set, but the high number is not. If only the upper bound is given, the lower bound is assumed to be zero (i.e., we can rewrite the above line as randint(ntrials, size=ntrials)). The last input indicats the number of samples to draw (as always, use randint? to find out more).
Q. Examine the values of i. What values do you find?
The result i provides a list of integers between 0 and 999. These values specify the trials to use in creating the resampled EEG. This resampled EEG will contain the same number of trials as the original EEG (i.e., 1,000 trials) but in a different order and with possibly repeated trials. For example, if the sampling with replacement procedure returns
i = [10, 941, 3, 400, 10, ...
then the first and fifth trials of the resampled EEG will equal the eleventh trial of the original EEG (remember that Python indices start at zero). We create the resampled EEG in Python as follows:
EEG0 = EEGa[i] # Create the resampled EEG.
In this code we use the variable i as the index to the rows of EEGa.
Q. What is the shape of the new variable EEG0? Is this shape consistent with the original EEG datasets?
That completes step 1 of the resampling procedure.
YouTubeVideo('bUzuNojLUik')
Step 2¶
This step is easy: we create a resampled ERP from the resampled EEG data. Computing the resampled ERP requires only one line of code in Python:
ERP0 = EEG0.mean(0) # Create the resampled ERP
Q. What is the difference between the resampled EEG and resampled ERP? Explain your answer in words.
Q. Plot the resampled ERP that we created. What does it look like?
YouTubeVideo('feQk_vKloXk')
Step 3¶
In the first two steps of the resampling procedure we created a single resampled ERP. In step 3 we are instructed to repeat this procedure 3,000 times and create a distribution of ERPs. How can we do so? One potential solution is to cut and paste the code we developed over and over again, for example:
i = randint(ntrials, size=ntrials); # Draw integers,
EEG1 = EEGa[i]; # ... create resampled EEG,
ERP1 = EEG1.mean(0); # ... create resampled ERP.
i = randint(ntrials, size=ntrials); # Draw integers,
EEG2 = EEGa[i]; # ... create resampled EEG,
ERP2 = EEG2.mean(0); # ... create resampled ERP.
i = randint(ntrials, size=ntrials); # Draw integers,
EEG3 = EEGa[i]; # ... create resampled EEG,
ERP3 = EEG3.mean(0); # ... create resampled ERP.
In these lines we have created three resampled ERPs, each with its own variable name. We could, of course, repeat this procedure and eventually define the variable ERP3000.
Q. Is defining the resampled ERPs in this way a good idea?
A. No! We should let the computer execute this repeated procedure for us. If you find yourself cutting and pasting the same code over and over again, you’re probably doing something inefficient, inelegant, and error-prone.
A better approach to create the 3,000 resampled ERPs is with a for-loop. We do so in Python with the for statement:
def bootstrapERP(EEGdata, size=None): # Steps 1-2
""" Calculate bootstrap ERP from data (array type)"""
ntrials = len(EEGdata) # Get the number of trials
if size == None: # Unless the size is specified,
size = ntrials # ... choose ntrials
i = randint(ntrials, size=size) # ... draw random trials,
EEG0 = EEGdata[i] # ... create resampled EEG,
return EEG0.mean(0) # ... return resampled ERP.
# Step 3: Repeat 3000 times
ERP0 = [bootstrapERP(EEGa) for _ in range(3000)]
ERP0 = array(ERP0) # ... and convert the result to an array
In the first line, we define a function that performs the calculations that we wish to repeat. In this case, the function performs steps 1 and 2 of the bootstrapping procedure. The last two lines call the function 3,000 times and convert the result from a list into an array. This completes step 3 of the bootstrapping procedure.
Note that in the definition of bootstrapERP, we included an argument (size) that has a default value (None). This lets us assume that we want the resampled dataset to be the same size as the original, which is true for right now. Later, however, we will reuse this function but will not want the resampled data to be the same size as the original.
In Python it is common to see for-loops written in the form
`y = [f(x) for x in some_set]`
This will return a list datatype, which is why we had to convert it to an array in the code above. We could also have written the loop in an alternative way:
`ERP0 = zeros((3000, EEGa.shape[1]))`
`for k in range(3000):`
` ERP0[k, :] = bootstrapERP()`
Note that it is good practice, but not required, to define a function that contains the code you wish to repeat, especially if you might use it again later. This minimizes rewrites, and if there is a mistake then you only need to make a correction in one place.
YouTubeVideo('NLc93QESVZs')
Step 4¶
In this step of the bootstrapping procedure, we determine for each time point the values greater than 2.5% and less than 97.5% of all values. There are many ways to perform this operation in Python, perhaps the easiest being to sort from smallest to largest the 3,000 resampled ERP values at each time point. With the resampled values sorted in this way, we then find the resampled ERP value at index \(0.025 \times 3000 = 75\) and \(0.975 \times 3000 = 2925\). These indices correspond to the resampled ERP values greater than 2.5% of all values and greater than 97.5% of all values, respectively, and therefore define the lower and upper confidence intervals at each moment in time. We can compute both confidence intervals in Python, and (at last!) plot the ERP for condition A with confidence intervals computed using the bootstrapping procedure:
ERP0.sort(axis=0) # Sort each column of the resampled ERP
N = len(ERP0) # Define the number of samples
ciL = ERP0[int(0.025*N)] # Determine the lower CI
ciU = ERP0[int(0.975*N)] # ... and the upper CI
mnA = EEGa.mean(0) # Determine the ERP for condition A
plot(t, mnA, 'k', lw=3) # ... and plot it
plot(t, ciL, 'k:') # ... and plot the lower CI
plot(t, ciU, 'k:') # ... and the upper CI
hlines(0, 0, 1, 'b') # plot a horizontal line at 0
# ... and label the axes
labelPlot('ERP of condition A with bootstrap confidence intervals') # We define this function above!
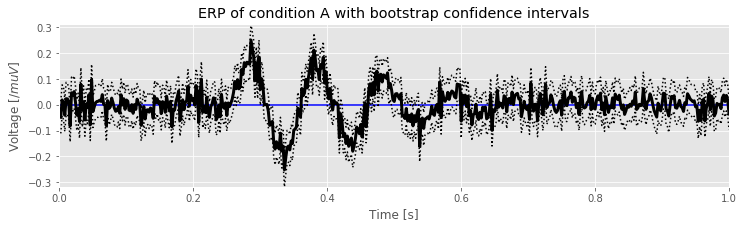
We can use these results to identify, for example, intervals in which the ERP differs significantly from zero by finding periods in which the confidence intervals do not include zero. The advantage of the bootstrapping procedure over other approaches is that this procedure requires few assumptions about the distribution of the statistic of interest, and that we use the observed data to probe the distribution of the statistic. The disadvantage of the bootstrapping procedure is that it is computationally intensive. Here we considered 3,000 resamplings, but we could easily consider more.
Q. Compare the confidence intervals in the plot above (bootstrap confidence intervals) to the CLT confidence intervals computed earlier. How are the two results similar or different? What happens to the confidence intervals if you change the number of resamplings in step 3 from 3,000 to 10,000?
Q. Compute the confidence intervals using the bootstrapping procedure for the ERP of condition B. What do you find?
A Bootstrap Test to Compare ERPs¶
YouTubeVideo('K6pgCxFdELc')
The bootstrapping procedure provides a powerful technique to construct confidence intervals for the ERPs using only the observed EEG measurements. We can apply a similar technique to search for significant differences between the ERPs in conditions A and B. To do so, we first choose a statistic, a measure of some attribute of the difference between the two ERPs. There are many choices, some informative and some not. Let’s choose as our statistic the maximum absolute value of the difference in the ERPs across time. Computing this statistic is straightforward in Python:
mbA = mean(EEGa,0) # Determine ERP for condition A
mnB = mean(EEGb,0) # Determine ERP for condition B
mnD = mnA - mnB # Compute the differenced ERP
stat = max(abs(mnD)) # Compute the statistic
print('stat = {:.4f}'.format(stat))
stat = 0.2884
Q. Given the value we determined for stat, are the ERPs for the two conditions different?
YouTubeVideo('390ywma7S3U')
In isolation, the numerical value for stat is not very useful or interesting. Is the value for stat consistent with noisy scalp EEG data lacking an evoked response? Or is the value for stat large and unexpected to occur unless the ERPs in the two conditions are different? To make the statistic useful, we need stat to be interpretable, which we pursue here through a bootstrapping procedure. We assume that no difference exists between the two conditions; in the language of statistics, this is called the null hypothesis. If the null hypothesis holds, then we can pool all the EEG signals together from both conditions (for a total of 2,000 trials) and draw from this combined distribution to create resampled ERPs representative of either condition.
It may seem odd to create pseudodata by selecting trials across both conditions; intuitively, we may expect the data to differ in these two conditions and feel uncomfortable making a pseudodata set that includes trials from both conditions. But under the null hypothesis, we assume no difference between the EEG responses in conditions A and B, and we are therefore free to create pseudodata drawing from trials in both conditions. We do so with the goal of creating a distribution of values for stat under the null hypothesis that conditions A and B exhibit no difference. We then compare the observed value of stat with this distribution of stat values. If there is a difference between the two conditions, we expect to find the observed value of stat to be very different from the distribution of stat values generated from the pseudodata under the null hypothesis.
To create the distribution of stat values under the null hypothesis of no difference between the two conditions, we perform a bootstrap test. The idea is similar to the bootstrapping procedure used to construct the confidence intervals for the ERPfig. We proceed as follows:
Merge the 1,000 trials each of EEG data from conditions A and B to form a combined distribution of 2,000 trials.
Sample with replacement 1,000 trials of EEG data from the combined distribution, and compute the resampled ERP.
Repeat step 2 and compute a second resampled ERP.
Compute the statistic, the maximum absolute value of the difference between the two resampled ERPs.
Repeat steps 2-4, 3,000 times to create a distribution of statistic values.
Compare the observed statistic to this distribution of statistic values. If the observed statistic is greater than 95% of the bootstrapped values, then reject the null hypothesis that the two conditions are the same.
The code to implement this procedure is similar to the bootstrapping procedure that we have already implemented to compute the confidence intervals for the ERP:
EEG = vstack((EEGa, EEGb)) # Step 1. Merge EEG data from all trials
seed(123) # For reproducibility
def bootstrapStat(EEG): # Steps 2-4.
mnA = bootstrapERP(EEG, size=ntrials) # Create resampled ERPa. The function 'bootstrapERP' is defined above!
mnB = bootstrapERP(EEG, size=ntrials) # Create resampled ERPb
mnD = mnA - mnB # Compute differenced ERP
return max(abs(mnD)) # Return the statistic
# Resample 3,000 times
statD = [bootstrapStat(EEG) for _ in range(3000)]
In this code, we first combine EEGa and EEGb in a new variable EEG.
Then, as before, we define the function bootstrapStat which performs the operations that we wish to repeat. Both of the first two lines of the function call bootstrapERP, the function that we defined earlier to compute a resampled ERP. Note that in this case, we call bootstrapERP with size=ntrials. When we combined the original datasets in EEG, we generated a dataset with twice the number of trials, but we still wish to perform the bootstrap procedure to create a resampled ERP using the original number of trials (1,000). The last two lines of the function compute the resampled difference and return the statistic. Finally, we repeat the procedure 3,000 times using a for-loop.
YouTubeVideo('iefCPGHd5vY')
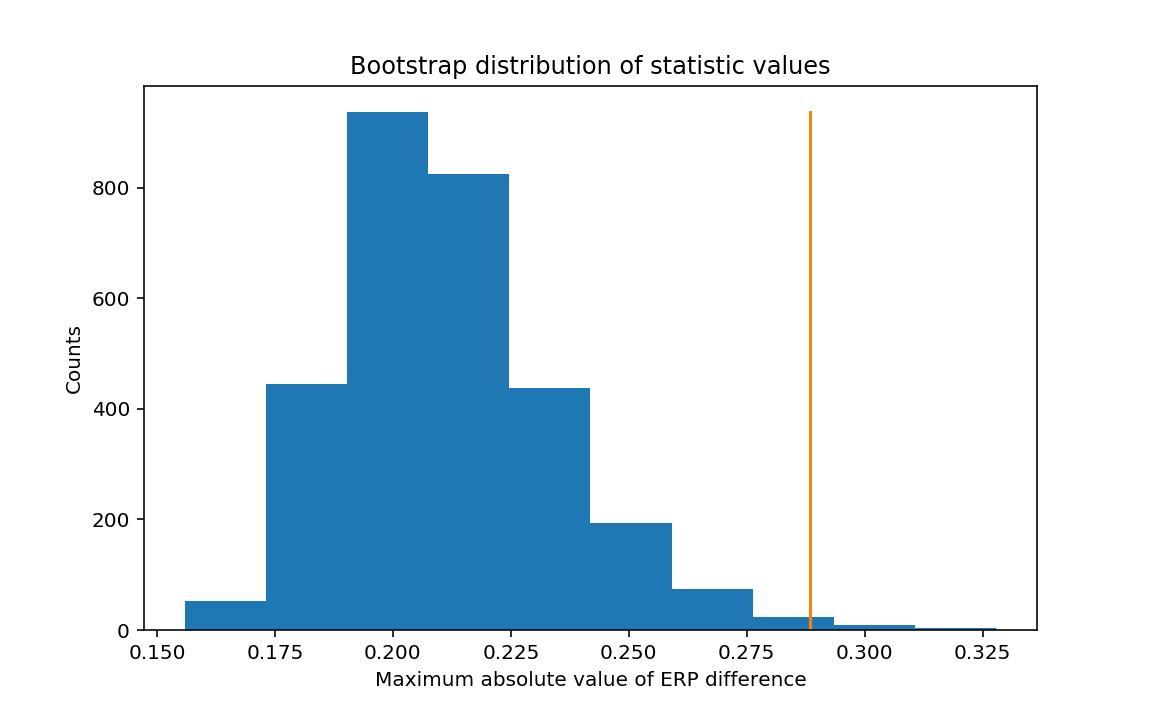
The figure above shows the distribution of values for the test statistic under the null hypothesis of no difference between the two conditions. The orange line indicates observed statistic from the EEG data.
The seed() function controls the random numbers that are generated. This ensures that when you recreate the plot above, yours will look identical. Nonetheless, if you remove (or comment out) this statement, your plot should still look very similar as the distribution should change only slightly.
Q. See if you can write code to generate this plot using the hist() function from the NumPy module.
Q. Given the distribution of statD values shown above, and the value of stat computed from the original data, can we conclude that the difference between the two conditions is significant with this statistic?
A. Yes. Under the null hypothesis, the distribution fo the statistic ranges from approximately 0.15 to 0.33. The observed statistic stat = 0.2884 exceeds most values in this distribution. Computing sum(statD > stat) we find in this example that only 18 of the 3,000 values in the distribution exceed the observed statistic. This corresponds to a proportion of 18/3000 = 0.006. We therefore reject the null hypothesis of no difference between the ERPs of conditions A and B. This result may be surprising, given how similar the two ERPs appear and the large variability in their differences (see figure).
This result illustrates the power of the bootstrapping procedure. We proposed a complicated statistic (the maximum absolute value of the difference between the two resampled ERPs). For this statistic, we do not possess an obvious formula to decide whether the resulting statistic is significant (we cannot rely on the CLT, for example). To determine significance, we employ a bootstrapping procedure (also known as a permutation test), which we can perform even for the relatively complicated statistic. In this way, we may devise complicated measures of data and construct error bars or compute statistical significance, provided our computational resources are sufficient.
Summary¶
In this notebook, we considered scalp EEG data recorded from a single electrode during an auditory task. The task consisted of two conditions, and we sought to uncover the difference in the EEG responses between the two conditions. We began with a visual inspection of the EEG recordings from individual trials and from all trials, and concluded that the data were quite noisy; any evoked response due to the stimulus was not obvious in the single-trial data.
To emphasize the evoked signal, we computed the ERP, which involved averaging the EEG signal across trials. By doing so, we uncovered interesting structure in condition A, but not much in condition B. We then developed two techniques to add error bars to an ERP. One technique relied on the central limit theorem, and the other technique involved a computationally expensive bootstrapping procedure. Both techniques suggested that the ERP in condition A differed significantly from zero following the stimulus at time 0.25 s.
Finally, we assessed whether the two ERPs from condition A and condition B differed. We did so through visual inspection, by comparing the differences in the ERPs, and by computing a statistic and assessing its significance through a bootstrapping procedure. Using the last procedure, we concluded that the ERP in the two conditions significantly differed.